The Best YouTube to MP3 Converters
Discover the best YouTube to MP3 converters available online and how they can efficiently convert YouTube videos to MP3 files.

From sharing personal experiences to showcasing artistic endeavors, Instagram video enables you to bring your ideas to life and connect with others through the art of visual storytelling.
Discover the best YouTube to MP3 converters available online and how they can efficiently convert YouTube videos to MP3 files.
Electric vehicles (EVs) are the future of personal transportation. With advancements in battery technology and the push towards sustainable energy,…
Instagram is one of the most popular social media platforms today, known for its captivating visuals and engaging content. With…
Videos have become an integral part of our daily lives. Whether it’s streaming movies, uploading content on social media, or…
We listen to our favorite tunes everywhere we go, whether it’s during our morning commute or while relaxing at home.…
From entertaining clips to educational tutorials, there is an abundance of video content available online. Reddit, a popular social media…
Video editing has become an essential skill for content creators, filmmakers, and enthusiasts alike. Whether you’re a beginner or a…
Navigating Connections: How to Message Someone on TikTok TikTok, the vibrant realm of short-form video content, is not only about…
Are you eager to learn how to save Instagram stories with music? Look no further! In this comprehensive guide, we…
Closing the Chapter: How to Delete Your TikTok Account TikTok, a dynamic platform for creative expression and connection, may occasionally…
Streamlining Your Following: How to Mass Unfollow on TikTok TikTok, the dynamic platform for creative expression, encourages users to engage…
Decoding “DC” on TikTok: Exploring its Meaning and Usage TikTok, a hub of trends, memes, and creative expressions, is known…
Navigating the TikTok Download Journey: A Comprehensive Guide TikTok, the cultural phenomenon that has taken the world by storm, offers…
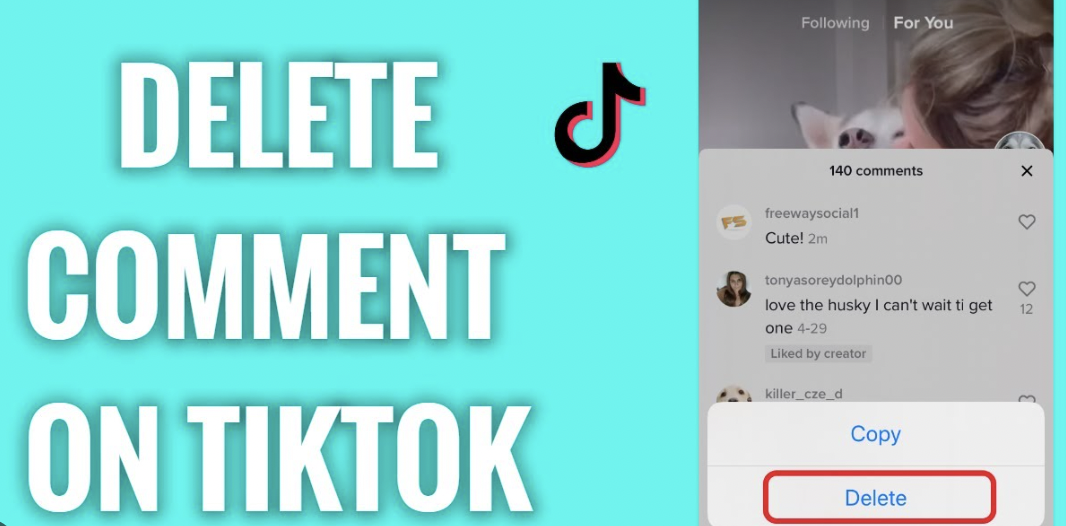
Streamlining Engagement: How to Delete a Comment on TikTok TikTok, the dynamic realm of short-form video content, encourages interaction and…
Lights, Camera, YouTube: A Comprehensive Guide to Creating Captivating Videos In the digital age, YouTube has emerged as a dynamic…
Reddit Reveries: Mastering the Art of Video Downloading Reddit, the self-proclaimed “front page of the internet,” is a treasure trove…
With the rapid advancement of technology, the concept of a quantum internet has emerged, revolutionizing the way we communicate and…
How to Watch Instagram Stories Anonymously: A Guide to Privacy Instagram Stories are a popular feature that allows users to…
In recent years, the world of reading has undergone a significant transformation with the rise of e-books. Digital reading experiences…
In the world of smartphones, the iPhone stands as a true pioneer. It revolutionized the way we communicate and paved…
When we think of the internet, we imagine a vast network of interconnected websites, search engines, and social media platforms…
Introduction In recent years, the rise of digital currencies has brought about a revolution in the banking industry. As traditional…
In recent years, we have witnessed a remarkable advancement in augmented reality (AR) technology. What was once seen as a…